
Risk Assessment: Risk Identification
The first operational phase of the RM process is the identification of risk. As a reminder, risk assessment includes risk identification as well as risk analysis and risk determination. Risk identification begins with the process of self-examination. As Sun Tzu stated, the organization must know itself to understand the risk to its information assets and where that risk resides. At this stage, managers must
- identify the organization’s information assets,
- classify them,
- categorize them into useful groups, and
- prioritize them by overall importance.
This can be a daunting task, but it must be done to identify weaknesses and the threats they present.
The RM process team must initially confirm or define the categories and classifications to be used for the information assets, once identified. Some organizations prefer to collect the inventory first and then see what natural categories and classifications emerge; those areas are discussed later in this module. Once the risk management team has its organization formalized, it begins with the first major task of risk identification.
Identification of Information Assets
The risk identification process begins with the identification and cataloging of information assets, including people, procedures, data, software, hardware, and networking elements. This step should be done without prejudging the value of each asset; values will be assigned later in the process.
One of the toughest challenges in the RM process is identifying information assets with precision for the purposes of risk management. In the most general sense, an information asset is any asset that collects, stores, processes, or transmits information, or any collection, set, or database of information that is of value to the organization. For these purposes, the terms data and information are commonly used interchangeably. In some RM efforts, the information and its supporting technology—hardware, software, data, and personnel—are defined separately, and the decision whether to include a specific category or component is made by the RM process team.
Some commercial RM applications simplify the decision by separating information assets from media. Media in this context include hardware, integral operating systems, and utilities that collect, store, process, and transmit information, leaving only the data and applications designed to directly interface with the data as information assets for the purposes of RM. When the application interfaces with an external database or data file (data set), each is treated as a separate, independent information asset. When an application has data that is integral to its operations, it is treated as a single information asset.
By separating components that are much easier to replace (hardware and operating systems) from the information assets that are in some cases almost irreplaceable, the RM effort becomes much more straightforward. After all, what is the organization most concerned with? Is it the physical server used to host a critical application? Or is it the application and its data? Servers, switches, routers, and most host technologies are relatively interchangeable. If a server dies, the organization simply replaces it and then reloads the applications and data that give that server purpose in the organization. If an application dies, the replacement effort may be much more substantial than simply reinstalling an off-the-shelf application. Most core applications are heavily customized or even custom-developed for a particular purpose. This is not to insinuate that some assets don’t have value to the organization, but that they are not necessarily integral to an RM program.
Some organizations choose to focus narrowly on their initial RM process and then add information assets in later iterations. They may begin with data and core applications, add communications software, operating systems, and supporting utilities, and finally add physical assets. The bottom line is that the RM process team should decide and define exactly what constitutes an information asset for the purposes of the RM effort, so it can effectively and efficiently manage the scope and focus of the effort.
Table 4-1 shows a model outline of some information assets the organization may choose to incorporate into its RM effort. These assets are categorized as follows:
- The people asset can be divided into internal personnel (employees) and external personnel (nonemployees). Insiders can be further divided into employees who hold trusted roles and therefore have correspondingly greater authority and accountability, and regular staff members who do not have any special privileges. Outsiders consist of other users who have access to the organization’s information assets; some of these users are trusted, and some are untrusted.
- Procedures can be information assets because they are used to create value for the organization. They can be divided into
- IT and business standard procedures and
- IT and business-sensitive procedures.
Sensitive procedures have the potential to enable an attack or to otherwise introduce risk to the organization. For example, the procedures used by a telecommunications company to activate new circuits pose special risks because they reveal aspects of the inner workings of a critical process, which can be subverted by outsiders for the purpose of obtaining unbilled, illicit services.
- The data asset includes information in all states: transmission, processing, and storage. This is an expanded use of the term data, which is usually associated with data sets and databases, as well as the full range of information used by modern organizations.
- Software can be divided into applications, operating systems, utilities, and security components. Software that provides security controls may fall into the operating systems or applications category but is differentiated by the fact that it is part of the InfoSec control environment and must therefore be protected more thoroughly than other systems components.
- Hardware can be divided into
- the usual systems devices and their peripherals and
- the devices that are part of InfoSec control systems.
The latter must be protected more thoroughly than the former.
- Networking components can include networking devices (such as firewalls, routers, and switches) and the systems software within them, which is often the focal point of attacks, with successful attacks continuing against systems connected to the networks. Of course, most of today’s computer systems include networking elements. You will have to determine whether a device is primarily a computer or primarily a networking device. A server computer that is used exclusively as a proxy server or bastion host may be classified as a networking component, while an identical server configured as a database server may be classified as hardware. For this reason, networking devices should be considered separately rather than combined with general hardware and software components.

In some corporate models, this list may be simplified into three groups: people, processes, and technology. Regardless of which model is used in the development of risk assessment methods, an organization should ensure that all its information resources are properly identified, assessed, and managed for risk.
As mentioned previously, the entire set of assets in some risk management programs is divided into RM information assets, such as applications, application-based data, other independent data sets or collections, and media—essentially anything that can collect, store, process, or transmit data. The media are used for grouping access to the asset but are not valued and evaluated as a critical function of the risk identification step. This simplistic approach may be best for organizations just starting out in RM.
Identifying Hardware, Software, and Network Assets
Many organizations use asset inventory systems to keep track of their hardware, network, and software components. Numerous applications are available, and it is up to the chief information security officer (CISO) or chief information officer (CIO) to determine which application best serves the needs of the organization. Organizations that do not use an off-the-shelf inventory system must create an equivalent manual or automated process. Automated systems are valuable because hardware is already identified by model, make, and location. Note that the number of items and large quantity of data for each item will quickly overwhelm any manual system and might stress poorly designed automated inventory systems.
Whether automated or manual, the inventory process requires a certain amount of planning. Most importantly, you must determine which attributes of each of these information assets should be tracked. That determination will depend on the needs of the organization and its risk management efforts as well as the preferences and needs of the InfoSec and IT communities. When deciding which attributes to track for each information asset, consider the following list of potential attributes:
- Name—Some organizations may have several names for the same product, and each of them should be cross-referenced in the inventory. By having redundant names for its assets, the organization gains flexibility and allows different units to have their own designations. However, the different names should be cross-listed as synonyms in inventory, and one of the asset names should be designated as the authoritative name. No matter how many names you track or how you select a name, always provide a definition of the asset in question. A recommended practice is to adopt naming standards that do not convey critical information to potential system attackers. For instance, a server named CASH_1 or HQ_FINANCE may entice attackers.
- Asset tag—This is used to facilitate the tracking of physical assets. Asset tags are unique numbers assigned to assets and permanently affixed to tangible assets during the acquisition process.
- Internet Protocol (IP) address—This attribute may be useful for network devices and servers at some organizations, but it rarely applies to software. This practice is limited when the organization uses the Dynamic Host Configuration Protocol (DHCP) within TCP/IP, which reassigns IP numbers to devices as needed. In such cases, there is no value in using IP numbers as part of the asset-identification process.
- Media Access Control (MAC) address—As per the TCP/IP standard, all network-interface hardware devices have a unique number called the MAC address (also called an “electronic serial number” or a “hardware address”). The network operating system uses this number to identify specific network devices. The client’s network software uses the address to recognize traffic that it needs to process. In most settings, MAC addresses can be a useful way to track connectivity, but they can be spoofed by some hardware/software combinations.
- Asset type—This attribute describes the function of each asset. For hardware assets, a list of possible asset types that includes servers, desktops, networking devices, and test equipment should be developed. For software assets, the organization should develop a list that includes operating systems, custom applications by type (accounting, human resources, or payroll, to name a few), and packaged applications and/or specialty applications (such as firewall programs). The degree of specificity is determined by the needs of the organization. Asset types can be recorded at two or more levels of specificity by first recording one attribute that classifies the asset at a high level and then adding attributes for more detail. For example, one server might be listed as follows:
DeviceClass = S (server)
DeviceOS = Win16 (Windows 2016)
DeviceCapacity = AS (Advanced Server)
- Serial number—This is a number that uniquely identifies a specific device. Some software vendors also assign a software serial number to each instance of the program licensed by the organization.
- Manufacturer name—This attribute can be useful for analyzing threat outbreaks when specific manufacturers announce specific vulnerabilities.
- Manufacturer’s model or part number—This number identifies exactly what the asset is, and can be very useful in the later analysis of vulnerabilities because some threats apply only to specific models of certain devices and/or software components.
- Software version, update revision, or FCO number—This attribute includes information about software and firmware versions and, for hardware devices, the current field change order (FCO) number. An FCO occurs when a manufacturer performs an upgrade to a hardware component at the customer’s premises. Tracking this information is particularly important when inventorying networking devices that function mainly through the software running on them.
- Software licensing data—The nature and number of an organization’s software licenses, as well as where they are deployed, can be a critically important asset. Because licenses for software products are often tied to specific version numbers, geographic locations, or even specific users, this data may require specialized efforts to track.
- Physical location—This attribute does not apply to software elements. Nevertheless, some organizations may have license terms that indicate where software can be used. This may include systems leased at remote locations, often described as being “in the cloud.”
- Logical location—This attribute specifies where an asset can be found on the organization’s network. The logical location is most applicable to networking devices and indicates the logical network segment that houses the device.
- Controlling entity—This refers to the organizational unit that controls the asset. In some organizations, a remote location’s on-site staff could be placed in control of network devices; in other organizations, a central corporate group might control all the network devices.
Consider carefully what should be tracked for specific assets. Often, larger organizations find that they can effectively track only a few valuable facts about the most critical information assets. For instance, a company may track only an IP address, server name, and device type for its mission-critical servers. The organization might forgo additional attribute tracking on all devices and completely omit the tracking of desktop or laptop systems.
Identifying People, Procedures, and Data Assets
Human resources, documentation, and data information assets are not as readily identified and documented as hardware and software. Responsibility for identifying, describing, and evaluating these information assets should be assigned to managers who possess the necessary knowledge, experience, and judgment. As these assets are identified, they should be recorded via a reliable data-handling process like the one used for hardware and software.
The record-keeping system should be flexible, allowing you to link assets to attributes based on the nature of the information asset being tracked. Basic attributes for various classes of assets include the following:
People
- Position name/number/ID—Avoid names; use position titles, roles, or functions
- Supervisor name/number/ID—Avoid names; use position titles, roles, or functions
- Security clearance level
- Special skills
Procedures
- Description
- Intended purpose
- Software/hardware/networking elements to which the procedure is tied
- Location where procedure documents are stored for reference
- Location where documents are stored for update purposes
Data
- Classification
- Owner/creator/manager
- Size of data structure
- Data organization used (for example, hierarchical, sequential, or relational)
- Online or offline; if online, whether accessible from outside the organization or not
- Physical location
- Media access method (for example, through user client desktops, laptops, or mobile media)
- Backup procedures, timeline, and backup storage locations
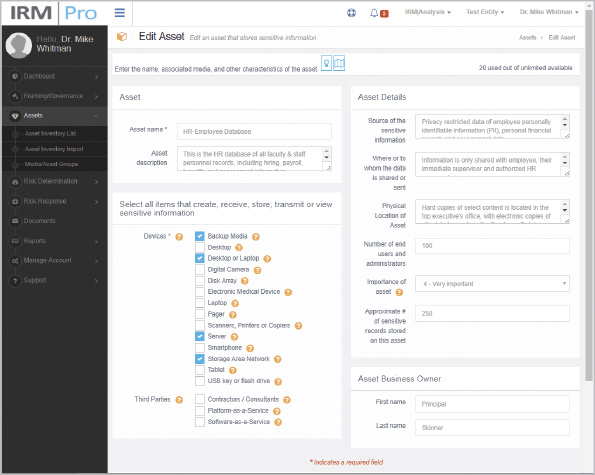
As you will learn later in the text, a number of applications can assist with the collection, organization, and management of these inventories. As shown in Figure 4-2, Clearwater Compliance’s Information Risk Management (CC|IRM) application has detailed fields in its asset inventory list to assist in the inventory and description of information assets.
Classifying and Categorizing Information Assets
Once the initial inventory is assembled, you must determine whether its asset categories are meaningful to the organization’s risk management program. Such a review may cause managers to further subdivide the categories presented in Table 4-1 or create new categories that better meet the needs of the risk management program. For example, if the category “Internet components” is deemed too general, it could be further divided into subcategories of servers, networking devices (routers, hubs, switches), protection devices (firewalls, proxies), and cabling.
The inventory should also reflect the sensitivity and security priority assigned to each information asset. A data classification scheme should be developed (or reviewed, if already in place) that categorizes these information assets based on their sensitivity and security needs. Consider the following classification scheme for an information asset: confidential, internal, and public. Confidential describes assets that must be protected as critical to the operations and reputation of the organization, such as strategic and marketing plans. Internal would describe assets that are for official use and should not be released to the public, like an internal phone directory or memorandum. Public would describe anything that can be shared with the general public, like Web content. Each of these classification categories designates the level of protection needed for an information asset. Some asset types, such as personnel, may require an alternative classification scheme that identifies the InfoSec processes used by the asset type. For example, based on need-to-know and right-to-update policies, an employee might be given a certain level of security clearance, which identifies the level of information that individual is authorized to use.
For organizations that need higher levels of security for very sensitive data, such as research and development (R&D) data, additional levels can be added above “confidential.” Classification categories must be comprehensive and mutually exclusive. “Comprehensive” means that all assets fit into a category; “mutually exclusive” means that each asset fits in only one category. A comprehensive scheme is important for ensuring that all assets are included if they fit in multiple locations.
Assessing the Value of Information Assets
As each information asset is identified, categorized, and classified, a relative value must be assigned to it. Relative values are comparative judgments intended to ensure that the most valuable information assets are given the highest priority when managing risk. It may be impossible to know in advance—in absolute economic terms—what losses will be incurred if an asset is compromised; however, a relative assessment helps to ensure that the higher-value assets are protected first.
As each information asset is assigned to its proper category, posing the following basic questions can help you develop the weighting criteria to be used for information asset valuation or impact evaluation.
How critical is the asset to the success of the organization? When determining the relative importance of each information asset, refer to the organization’s mission statement or statement of objectives. From this source, determine which assets are essential for meeting the organization’s objectives, which assets support the objectives, and which are merely adjuncts.
How much does the information asset contribute to revenue generation? The relative value of an information asset depends on how much revenue it generates—or, in the case of a nonprofit organization, how critical it is to service delivery. Some organizations have different systems in place for each line of business or service they offer. Which of these assets plays the biggest role in generating revenue or delivering services?
How much does the information asset contribute to profit generation? Managers should evaluate how much profit depends on a particular asset. For instance, at Amazon.com, some servers support the book sales operations, others support the auction process, and still others support the customer book review database. Which of these servers contributes the most to profitability? Although important, the review database server does not directly generate profits. Note the distinction between revenues and profits: Some systems on which revenues depend operate on thin or nonexistent margins and do not generate profits after expenses are paid. In nonprofit organizations, you can determine what percentage of the agency’s clientele receives services from the information asset being evaluated.
How expensive is the information asset to replace? Sometimes an information asset acquires special value because it is unique. Organizations must control the risk of loss or damage to such unique assets—for example, by buying and storing a backup device. These storage devices must be periodically updated and tested, of course.
How expensive is the information asset to protect? Some assets are by their nature difficult to protect, and formulating a complete answer to this question may not be possible until the risk identification phase is complete, because the costs of controls cannot be computed until the controls are identified. However, you can still make a preliminary assessment of the relative difficulty of establishing controls for each asset.
How much embarrassment or liability would the asset’s loss or compromise cause? Almost every organization is aware of its image in the local, national, and international spheres. Loss or exposure of some assets would prove especially embarrassing. Microsoft’s image, for example, was tarnished when an employee’s computer system became a victim of the QAZ Trojan horse and a version of Microsoft Office was stolen as a result.
You can use a worksheet such as the one shown in Table 4-2 to collect the answers to the preceding list of questions for later analysis. You may also need to identify and add other institution-specific questions to the evaluation process.

Throughout this module, numbers are assigned to example assets to illustrate the concepts being discussed. This highlights one of the challenging issues in risk management. While other industries use actuarially derived sources to make estimates, InfoSec risk management lacks such data. Many organizations use a variety of estimating methods to assess values. Some in the industry question the use of “guesstimated” values in calculations with other estimated values, claiming this degree of uncertainty undermines the entire risk management endeavor. Research in this field is ongoing, and you are encouraged to study the sections later in this module that discuss alternative techniques for qualitative risk management. Figure 4-3 illustrates a simplistic method that can be used to value an information asset by determining its “importance,” as shown in the Clearwater Compliance IRM application.

Prioritizing (Rank-Ordering) Information Assets
The final step in the risk identification process is to prioritize, or rank-order, the assets. This goal can be achieved by using a weighted table analysis similar to the one shown in Table 4-3 and discussed elsewhere in this text. In this process, each information asset is listed in the first column. Next, the relevant criteria that the organization wants to use to value the assets are listed in the top row. Next, each criterion is assigned a weight or value that typically sums to 1.0, 10, 100, or some other value that is easy to sum. The use of these weights is what gives this analysis its name. Next, the organization assigns a value to each asset, again using a scale of 0 to 1, 0 to 5, 0 to 10, or 0 to 100, based on the particular criteria value. Table 4-3 uses values from 0 to 5, corresponding to a simple scale of 1 = not important to 5 = critically important (zero is used to indicate “not applicable”). Finally, each information asset’s cell values are multiplied by the criteria weights and then summed to create the weighted score for that information asset. Sorting the table by the weighted score results in a prioritized list of information assets. Such tables can be used as a method of valuing information assets by ranking various assets based on criteria specified by the organization. This method may prove to be much more straightforward than a raw estimation based on some other more ambiguous assessment.

Threat Assessment
As mentioned at the beginning of this module, the goal of risk identification is to assess the circumstances and setting of each information asset to reveal any vulnerabilities. Armed with a properly classified inventory, you can assess potential weaknesses in each information asset—a process known as threat assessment. If you assume that every threat can and will attack every information asset, then the project scope becomes too complex. To make the process less unwieldy, each step in threat identification and vulnerability identification is managed separately and then coordinated at the end. At every step, the manager is called on to exercise good judgment and draw on experience to make the process function smoothly.
Some organizations have implemented processes to maintain ongoing vigilance in the threat environment in which they operate. This process of threat intelligence identifies and collects information about potential threats that may present risk to the organization.
Identifying Threats
Module 2 identified 12 categories of threats to InfoSec, which are listed alphabetically in Table 4-4. Each of these threats presents a unique challenge to InfoSec and must be handled with specific controls that directly address the particular threat and the threat agent’s attack strategy. Before threats can be assessed in the risk identification process, however, each threat must be further examined to determine its potential to affect the targeted information asset. In general, this process is referred to as threat assessment.

Assessing Threats
Not all threats endanger every organization, of course. Examine each of the categories in Table 4-4 and eliminate any that do not apply to your organization. It is unlikely that an organization can eliminate an entire category of threats, but doing so speeds up the threat assessment process.
The amount of danger posed by a threat is sometimes difficult to assess. It may be tied to the probability that the threat will attack the organization, or it may reflect the amount of damage that the threat could create or the frequency with which the attack may occur. The big question every organization wants to answer is: Which threats represent the greatest danger to this organization’s information assets in its current environment? Posing the following questions can help you find an answer by understanding the various threats the organization faces and their potential effects on an information asset:
How much actual danger does this threat represent to our information assets? If there is no actual danger, a perceived threat can be safely ignored. For example, the odds of certain natural disasters vary greatly based on an organization’s geographic locations. An organization located on the plains of Oklahoma shouldn’t worry about tidal waves, mudslides, or other events that are extremely uncommon in that region. Similarly, an organization that doesn’t use a particular software or hardware package doesn’t need to worry about threats to vulnerabilities in those items.
Is this threat internal or external? Some threat environments require different approaches, while some defenses address threats from multiple environments. Understanding the potential source of a threat helps to prioritize it.
How probable is an attack by this threat? Determining the probability that an attack will occur from a threat includes understanding how widely known the attack is (pervasiveness) and how many threat agents can execute the attack.
How probable is a successful attack by this threat? A threat with a low probability of success is less concerning than one with a high probability of success. Some of the attacks conducted by threats require extremely complicated attack exploits or highly sophisticated attack skills. The more complicated the exploit or the more expert the attacker must be for the attack to occur, the less the organization should worry about it. In summary, the previous question asks, “Could I be attacked by this threat?” while this question asks, “In an attack, would this threat be able to access my information assets?”
How severe would the loss be if this threat is successful in attacking? Of equal concern is understanding what damage could result from a successful attack by a threat. A threat with a high probability of success that would cause only minor damage is of less concern than a threat with a lower chance of success that would create a much greater loss to the organization.
How prepared is the organization to handle this threat? If the organization is ill prepared to handle an attack from a specific threat, it should give priority to that threat in its preparations and planning. This issue becomes increasingly important when rolling out new technologies, starting new business ventures, or making any other change in the organization in which the InfoSec function finds itself in new competitive and threat environments.
How expensive is it to protect against this threat? Another factor that affects the danger posed by a particular threat is the amount it would cost to protect against that threat. Some threats carry a nominal cost to protect against (for example, malicious code), while others are very expensive, as in protection from forces of nature. Especially in small to medium-sized businesses (SMBs), the budget may be insufficient to cover all the defensive strategies the organization would like to implement; as a result, some threat prioritization simply may boil down to available funds. Here again, the manager ranks, rates, or attempts to quantify the level of danger associated with protecting against a particular threat by using the same techniques used for calculating recovery costs.
How expensive is it to recover from a successful attack by this threat? One of the calculations that guides corporate spending on controls is the cost of recovery operations if an attack occurs and is successful. At this preliminary phase, it is not necessary to conduct a detailed assessment of the costs associated with recovering from a particular attack. Instead, organizations often create a subjective ranking or listing of the threats based on recovery costs. Alternatively, an organization can assign a rating for each threat on a scale of 1 to 5, where a 1 represents inexpensive recovery costs and a 5 represents extremely expensive costs. If the information is available, a raw value such as $5,000, $10,000, or $2 million can be assigned. In other words, the goal at this phase is to provide a rough assessment of the cost to recover normal business operations if the attack interrupts them.
You can use both quantitative and qualitative measures to rank values. The preceding questions can be used as categories in a weighted table analysis of threats, like the asset analysis described previously. Because information in this case is preliminary, the organization may simply want to identify threats that top the list for each question.
The preceding list of questions may not cover everything that affects risk assessment. An organization’s specific guidelines or policies should influence the process and will inevitably require that some additional questions be answered.
Prioritizing Threats
Just as it did with information assets, the organization should conduct a weighted table analysis with threats. The organization should list the categories of threats it faces and then select categories that correspond to the questions of interest described earlier. Next, it assigns a weighted value to each question category and then assigns a value to each threat with respect to each question category. The result is a prioritized list of threats the organization can use to determine the relative severity of each threat facing its assets. In extreme cases, the organization may want to perform such an assessment of each threat by asset, if the severity of each threat is different depending on the nature of the information asset under evaluation.
Vulnerability Assessment

Once the organization has identified and prioritized both its information assets and the threats facing those assets, it can begin to compare information assets to threats. This review leads to the creation of a list of vulnerabilities that remain potential risks to the organization. What are vulnerabilities? They are specific avenues that threat agents can exploit to attack an information asset. In other words, they are chinks in the asset’s armor—a flaw or weakness in an information asset, security procedure, design, or control that can be exploited accidentally or on purpose to breach security. For example, Table 4-5 analyzes the threats to a DMZ router and its possible vulnerabilities.
A list like the one in Table 4-5 should be created for each information asset to document its vulnerability to each possible or likely attack. This list is usually long and shows all the vulnerabilities of the information asset. Some threats manifest themselves in multiple ways, yielding multiple vulnerabilities for that asset-threat pair. Of necessity, the process of listing vulnerabilities is somewhat subjective and is based on the experience and knowledge of the people who create the list. Therefore, the process works best when groups of people with diverse backgrounds work together in a series of brainstorming sessions. For instance, the team that reviews the vulnerabilities for networking equipment should include networking specialists, the systems management team that operates the network, InfoSec risk specialists, and even technically proficient users of the system.
The TVA Worksheet
At the end of the risk identification process, an organization should have
- a prioritized list of assets and
- a prioritized list of threats facing those assets.
Prioritized lists should be developed using a technique like the weighted table analysis discussed earlier.
The organization should also have a working knowledge of the vulnerabilities that exist between each threat and each asset. These lists serve as the starting point for the next step in the risk management process: risk assessment. The prioritized lists of assets and threats can be combined into a threats-vulnerabilities-assets (TVA) worksheet, in preparation for the addition of vulnerability and control information during risk assessment. Along one axis lies the prioritized set of assets. Table 4-6 shows the placement of assets along the horizontal axis, with the most important asset at the left. The prioritized list of threats is placed along the vertical axis, with the most important or most dangerous threat listed at the top. The resulting grid provides a convenient method of examining the “exposure” of assets, allowing a simple vulnerability assessment. We now have a starting point for our risk assessment, along with the other documents and forms.

Before you begin the risk analysis process, it may be helpful to create a list of the TVA “triples” to facilitate your examination of the severity of the vulnerabilities. For example, between Threat 1 and Asset 1, there may or may not be a vulnerability. After all, not all threats pose risks to all assets. If a pharmaceutical company’s most important asset is its research and development database and that database resides on a stand-alone network (one that is not connected to the Internet), then there may be no vulnerability to external hackers. If the intersection of T1 and A1 has no vulnerability, then the risk assessment team simply crosses out that box. It is much more likely, however, that one or more vulnerabilities exist between the two, and as these vulnerabilities are identified, they are categorized as follows:
T1V1A1—Vulnerability 1 that exists between Threat 1 and Asset 1
T1V2A1—Vulnerability 2 that exists between Threat 1 and Asset 1
T2V1A1—Vulnerability 1 that exists between Threat 2 and Asset 1 … and so on.
In the risk analysis phase discussed in the next section, not only are the vulnerabilities examined, the assessment team analyzes any existing controls that protect the asset from the threat or mitigate the losses that may occur. Cataloging and categorizing these controls is the next step in the risk identification process.
There is a key delineator here between risk identification and risk analysis: In developing the TVA spreadsheet, the organization is performing risk identification simply by determining whether an asset is at risk from a threat and identifying any vulnerabilities that exist. The extent to which the asset is at risk falls under risk analysis. The fine line between the two is part of the reason that many organizations follow the methodology outlined in Figure 4-1 described earlier in this module, but they merge risk identification, risk analysis, and risk evaluation into one logical process and just call it risk assessment.

Henryclarkethicalhacker @ gmail com, is the solution to any hacking service
ReplyDelete